| ■1文字にマッチさせる |
| /a./ |
「a」と、改行文字以外の文字1文字、という意味 |
| [abc] |
a/b/cのどれか1つがマッチするかチェックする。 |
| [^abc] |
a/b/c以外の1文字を含めばマッチします。 |
| [0-9] |
[0123456789]という意味です。 |
| ■複数の文字列にマッチさせる |
| /abc*/ |
「ab」が来て、次に「c」が0個以上ある、という意味になります。ですから、「ab」「abc」「abcccccc」といった文字列がすべてマッチします。 |
| /abc+/ |
「1個以上ある!」なので、「abc」「abccc」はマッチします。「ab」はマッチしません。 |
| /abc?/ |
「0個または1個ある」なので「ab」と「abc」両方マッチします。「abccc」もマッチします。 |
| /data{0-9}+/ |
「data01」「data125」「data8」はマッチします。「data」はマッチしません。 |
| /data{0-9}*/ |
「*」は「0個以上ある」なので、「+」と違い「data」「datafile」はマッチします。 |
| /a{1,5}/ |
「a」が「1個以上5個以下」となります。「aa」「aaaaa」がマッチします。 |
| /a{1,}/ |
「a」が1個以上、という意味です。(「/a+/」と同じ意味です) |
| /a{0,5}/ |
「●以下なら何でも良し!」としたい場合は、このように「0個以上」という表現を使う。 |
| /a{5}/ |
「{」「}」の間に数字を1つだけ記述すると、その数字の個数だけという意味になります。 |
| ■正規表現をカッコで囲む |
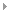 正規表現を「( )」で囲むと、そのカッコで囲まれた正規表現にマッチ文字列を自動的にスカラー変数に指定します。スカラー変数は、順番に「$1」「$2」「$3」・・・・という名前になります。 正規表現を「( )」で囲むと、そのカッコで囲まれた正規表現にマッチ文字列を自動的にスカラー変数に指定します。スカラー変数は、順番に「$1」「$2」「$3」・・・・という名前になります。 |
| /abc(.)egf$1/ |
「.」=「改行文字以外の文字なら何でもよいから1文字」という意味です。「abc」と来て、次に何でもいいので1文字来て、その後「efg」が来ることになります。そして「$1」にカッコに囲まれている「.」に当てはまった文字が指定されます。それが「efg」の後に来ると指定しています。 |
|
abcrefgrはマッチします。「abc」の後に、「r」が1文字来て、その後に「efg」が続きます。ここまでが「abc(.)efg」です。その後に来る「$1」ですが、カッコに囲まれている「.」に該当する「r」が、この「$1」に自動的に入ります。それが「efg」の後に来るわけです。 |
| /abc(.)(.*)$1$2/ |
カッコを2つ以上使う場合は、左から順番に「$1」「$2」「$3」・・・・という名前のスカラー変数に指定されます。まず「abc」が来て、次に改行文字以外の文字が1文字(これが$1になる)、その次に改行文字以外の文字が0文字以上(これが$2になる)、次に$1、そして次に$2と続きます。 |
| ■どれか1つにマッチさせる |
| 複数の文字列のうちどちらかにマッチする、という条件にしたい場合は、「|」を使います。 |
| /a|b|c/ |
「a」「b」「c」のうち、どれかにマッチする、という意味になる。 |
| $data=~/はし/; |
「$data」に「はし」という文字列が含まれている場合か、または「餃子」という文字が含まれている場合、マッチすることになる。 |
| ■マッチさせる位置を指定する |
| 文字列の特定の部分がマッチするかどうかをチェックします。例えば、文字列の最後がマッチするかどうか、なんてことをチェックする場合に使用します。 |
| /~data[0-9]*/ |
文字列の最初がマッチするかどうかチェックする |
| /data[0-9]*$/ |
「data」「data1」「data30」はマッチします。「datafile」「datalist」「dataです」はマッチしません。
※含まれているかを検索する |
| /^data[0-9]*$/ |
「data」「data1」「data30」はマッチします。「datafile」「datalist」「dataです」はマッチしません。
※完全一致を検索する |
| I'm from Japan. |
"I'm"と"from"と"Japan"の間にあるスペースが「単語境界」 |
| /abc\b/ |
「abc」はマッチしますが、「abcd」はマッチしません。 |
| /\bab/ |
最初の「\b」が単語境界を意味し、次に文字列「ab」が来ています。「ab」「abc」はマッチしますが、「aab」「bab」などにはマッチしません。 |
| /\babc\b/ |
「abc」という文字列の前後に「\b」を付けます。こうすると、「abc」にはマッチしますが、「aabc」や「abcd」にはマッチしません。 |